-
On Leadership and DevOps: Reflections from DevOpsDays
DevOpsDays Boston was this week and it was great. I took part in a breakout session about leadership in DevOps and it really got me thinking. I mentioned the breakout session in the BosOps chatroom and there was some interest in hearing more about it, so I thought I’d put a blog post together. The official topic was along the lines of “identifying and developing leadership in DevOps.” There were about 20 people in the session; almost all managers or leadership types.
Leadership
!=ManagementThe discussion quickly drifted away from leadership and towards management. This was pretty telling; a group of leaders couldn’t naturally converge on what leadership actually meant! In my experience, when people talk about leadership, they rarely define it. People seem to have a sentimental attitude towards leadership. Leaders often inspire and motivate people, evoking very strong emotions.
Management is less about leadership and more about organizations. I would argue that management is less about leading and more about following, but that’s a discussion for another day. Managers (especially in agile organizations) are resource schedulers. Their mission is to achieve the most efficient allocation of resources (time, people, money) as defined by the business. Just look at the core curriculum for a management degree: accounting, finance, economics, marketing–all geared towards teaching people how to achieve business objectives by allocating resources.
Oftentimes the best managers are also leaders, but it’s important to note that leadership is not the same skill set as management. Even more importantly, you can be a leader without being a manager, and vice versa. After floundering for a bit we tried to refocus the discussion on leadership and proposed that we try and define what leadership actually means. A theme quickly emerged on this topic: empathy.
It’s all about that empathy, that empathy
We enumerated several skills that had a common theme: effective communication, situational awareness, good listening, emotional intelligence, consensus building, diplomacy, big-picture thinking. All of these skills speak to one very important leadership quality: empathy.
Empathy is the ability to understand the experiences of others; to empathize with someone is to put yourself in their shoes. Sympathy, on the other hand, is feeling sorry for someone. They are often confused, but knowing the difference is important. Sympathizing with someone is quick and easy, empathizing requires more time and deliberation. Sympathy is useful to signal to another that you care about them, but doesn’t necessarily mean that you’re interested in what they’re feeling.
By empathizing with others, we become better equipped to solve problems that transcend our own problem domain–we become invested in the success of others. Empathy is key to bringing groups with disparate experiences together. Leaders demonstrate empathy out of sheer necessity. It’s impossible to lead others when you don’t understand their challenges, experiences, and concerns. Empathy makes finding common ground, motivating others, and building consensus easier. In short, empathy begets action.
Empathy is really the essence of DevOps. DevOps needs leaders to be successful. I have no data to prove it, but I doubt any successful implementation of DevOps has happened absent an abundance of leaders on both sides.
Leadership and power
The conversation quickly turned towards a discussion of leadership and power. We talked about some of the different kinds of power: legitimate, expert, and referent. Legitimate power is based on one’s position in an organization: a manager has legitimate power over his reports. Referent power is based on the ability to command loyalty: charismatic leaders can garner referent power by inspiring others to follow them. Expert power is based on one’s mastery of a sought-after skill set: an experienced engineer possesses expert power when other engineers rely on her to drive the technical direction of a project.
Legitimate power is not necessary for leadership. People who say they need legitimate power to lead are sorely mistaken and are not the type of leaders you want to hire or work for. Leaders focus on referent and expert power; they focus their energy on fostering relationships and building consensus. The exact manifestation of these things vary widely based on the organization, but a leader should be able to acquire power regardless of their position in the organization. The ability to acquire power without position is a key indicator of leadership. As a result, leaders often bubble to the surface.
Growing leaders
We learned very quickly that DevOps is not something you can buy. You have to grow the skills necessary to make DevOps successful. This means growing leaders. The group discussed the importance of giving people the opportunity to lead. When you identify someone as a potential leader, it’s important to give them a safe space to experiment with leadership. Give them a project that would afford them the opportunity to show some leadership. The key is to provide clear, concise, actionable feedback continuously throughout the process.
-
Puppet Module Documentation Generation with Rake and Puppet Strings
I have a confession: I love good documentation. I also love Puppet’s new documentation tool Strings, which is meant to supplant the rather fussy
puppet doccommand. Strings is built on the popular Ruby documentation tool YARD. Strings allows you to document your code using markdown (or RDoc) and generate beautiful documentation that’s easy to consume. I recommend checking out the Strings README for more comprehensive documentation on the format and configuration options. Strings is a Puppet Face and is delivered via a Puppet module. To use Strings, all you have to do is install theyardgem, and thepuppetlabs/stringsPuppet module:$ puppet module install puppetlabs/strings Notice: Preparing to install into /Users/ddanzilio/.puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /Users/ddanzilio/.puppet/modules └── puppetlabs-strings (v0.1.1) $ gem install yard Fetching: yard-0.8.7.6.gem (100%) Successfully installed yard-0.8.7.6 1 gem installed $ puppet help strings USAGE: puppet strings <action> Generate Puppet documentation with YARD. OPTIONS: --render-as FORMAT - The rendering format to use. --verbose - Whether to log verbosely. --debug - Whether to log debug information. ACTIONS: server Serve YARD documentation for modules. yardoc Generate YARD documentation from files. See 'puppet man strings' or 'man puppet-strings' for full help.I’ve started generating documentation with Strings for all of my Puppet modules and pushing it to the
gh-pagesbranch so it’s available in GitHub Pages. You can see an example of the kind of output generated with Strings by looking at the docs generated by my VirtualBox module here. I threw together a coupleraketasks to help with this and thought I would share:namespace :strings do doc_dir = File.dirname(__FILE__) + '/doc' git_uri = `git config --get remote.origin.url`.strip vendor_mods = File.dirname(__FILE__) + '/.modules' desc "Checkout the gh-pages branch for doc generation." task :checkout do unless Dir.exist?(doc_dir) Dir.mkdir(doc_dir) Dir.chdir(doc_dir) do system 'git init' system "git remote add origin #{git_uri}" system 'git pull' system 'git checkout gh-pages' end end end desc "Generate documentation with the puppet strings command." task :generate do Dir.mkdir(vendor_mods) unless Dir.exist?(vendor_mods) system "bundle exec puppet module install puppetlabs/strings --modulepath #{vendor_mods}" system "bundle exec puppet strings --modulepath #{vendor_mods}" end desc "Push new docs to GitHub." task :push do Dir.chdir(doc_dir) do system 'git add .' system "git commit -m 'Updating docs for latest build.'" system 'git push origin gh-pages' end end desc "Run checkout, generate, and push tasks." task :update => [ :checkout, :generate, :push, ] endYou can see a complete example of how I’ve configured this in my VirtualBox module here. I’m still working on an elegant way to generate this documentation with Travis. I know all the pieces are there, I just need to put them together in a pretty package. I’ll share that when I have time! Otherwise, let me know if you have any questions or suggestions to make this better!
-
The Seven Habits of Highly Effective Puppet Users: Treat Puppet like code
This post originally appeared on the Constant Contact Tech Blog. I’m reposting it here for continuity.
Note: This is the second post in a series based on a talk I gave at PuppetConf 2014: The Seven Habits of Highly Effective Puppet Users.
Of all the trends in operations, infrastructure as code is a major game changer. Infrastructure as code has brought a lot of new people—many of whom don’t necessarily consider themselves developers—into the software development world. This is, understandably, a strange world for many Ops folks. Traditionally, operations folks have had very different toolchains than their developer compatriots. This has made sense because they were solving different technical problems; the toolchains evolved in separate worlds. Why would an Ops person need to know how to use Git when they’re not writing any code?
Infrastructure as code is just one of the driving forces to unify toolchains between Dev and Ops. We’re now approaching our problems in similar ways—with code. The problem for many Ops folks undergoing this transition is that they don’t necessarily understand what it means to write code; they don’t necessarily know what good code, and good coding practices, look like. A lot of infrastructure code has evolved inside the Ops world and, consequentially, ends up looking very different from traditional code. Many people treat Puppet code like configuration files. It’s important to remember that infrastructure code is real code, and needs to be treated accordingly. OK, but what does that mean? Well, some of the basics include:
- version control
- documentation
- refactoring
- code review
- style
Let’s take a quick look at each of these fundamental elements of building and maintaining code:Version Control
The first step, actually the zeroth step, is to use version control. Developers use version control because code is their work product. If you’re using Puppet, or any other infracode language, your work product is code too. In the old days our work product was a server—big, beautiful, polished, and one-of-a-kind. Servers were configured by hand and it was hard to tell when things changed. Now, we write code. With code, it’s very easy to tell when things change; to do that, we use version control. There are tons of version control systems out there: Git, Mercurial, Subversion, Bazaar, Perforce, Visual Studio TFS, and AccuRev–just to name a few. There’s bound to be something to satisfy even the most contrarian of users. It doesn’t matter what version control system you use, just be sure to use something. Your infrastructure code is just too important not to check into a version control system.
Documentation
Now that you’re writing code, you’re going to have to learn how to write documentation. Back when we were handcrafting servers, we didn’t have a good place to put our documentation. It was a classic coupling problem. Many sysadmin shops have well-neglected Wikis or piles of outdated Word documents on a shared drive somewhere nobody remembers to look. With infrastructure as code, we can put our documentation right inside our source code. Developers document their code because it takes a lot of effort to understand what the code is doing by reading it; they know they’re not the only person who needs to understand the code. Adding new functionality or patching a bug is much easier when you can read documentation instead of having to reverse engineer the code to get context.
Well-documented code has inline documentation in some format that can be parsed and used to generate easy to read source documentation. Puppet has introduced a new tool called Strings to help infracoders generate pretty documentation from their code. Strings is built on top of the YARD documentation tool. It allows you to document your code using a variety of different formats.
Documentation best practices include:
- Inline documentation should fully document all parameters and variables used in classes and defined types.
- A README should explain how to use a module, what the module affects, the requirements of a module, and any other information necessary to use the module.
- No new functionality should be added without documentation.
- Documentation must not be an afterthought; it should be central to your development workflow.
- You should document your code as you go, because you’re probably not going to do it after the fact.
RefactoringRefactoring is a concept that will be foreign to many sysadmins. Refactoring is a continuous improvement practice where a developer regularly makes small improvements that do not change the external behavior of the code. These changes are geared towards improving readability, reducing complexity, and other improvements that make the code more maintainable or efficient. Refactoring should not change the API or the way the code behaves from a user’s perspective. Refactoring is a central aspect of Test Driven Development, a topic I’ll discuss in another post.
Code Review
Code review is also likely to be a fairly novel concept to traditional sysadmins. Before we had a way to express our infrastructure in code, there was no good way to submit your work for comprehensive peer review. Now our code changes can (and should) be reviewed by our peers before they make it into the codebase. This can be enormously beneficial for the code and the developer alike. Code review is also a great tool for communicating amongst team members. It is also a very effective teaching tool. Code review carries many of the same benefits of pair programming—bugs are caught earlier, mistakes (downtime) are avoided, team members learn from each other. There are a number of tools available to aide in this process; the most common tool is Gerrit. Code review shouldn’t be painful or disparaging; it’s simply an opportunity to get another pair of eyes on your code and to learn from the experience of others.
Style
Now that infrastructure is code, we need to make sure that the code is readable by everyone who needs to work on it. Adhering to a style guide is an important part of this. Coding styles can vary widely from person to person. A style guide helps to ensure that everybody understands the standards that the code is expected to meet. Puppet Labs has a style guide; you can automate checking your code’s compliance with the style guide using the puppet-lint gem. You can integrate puppet-lint into your development workflow to ensure that it checks your code every time it is committed to a shared repository. You can easily achieve this with your version control system’s hook mechanism or with a Continuous Integration system like Travis CI or Jenkins (I’ll talk more about Continuous Integration in a separate post). Style is substantive when we’re talking about code.
Treating Puppet like code is very important in order to write code that is reusable and easy to maintain. These concepts may be foreign to you, but there are plenty of good examples of this behavior amongst the community. I highly recommend you take a look at the Puppet Approved and Puppet Supported modules on the Puppet Forge for examples of good coding behavior. I’ve talked about some of the basics of treating Puppet like code, but it really is much more involved than what I’ve written here.
Over the course of this blog series, I’ll dig more in depth on what it means to write good Puppet code. Feel free to take a look at my PuppetConf presentation: Seven Habits of Highly Effective Puppet Users.
The next post in this series will be on designing for Puppet. Stay tuned!
-
Puppet Fileserver Offloading
I haven’t written much about our Puppet environment at Constant Contact since I started there just about a year ago; I was brought in to help with the transition to Puppet 3. A bit of information about our environment: we have a couple hundred developers committing to our Puppet code, with about 500 commits per week to our main Puppet repository which contains over 100,000 lines of (mostly custom) code. As for scale, we have five distinct deployment environments across three datacenters; in total we have about 6,000 servers. Each environment hosts a pair of Puppet masters in an active-active HA configuration behind a load balancer.
Constant Contact was a very early adopter of Puppet, and it really shows in the code. We began using Puppet around version 0.24.8; well before paramterized classes would be introduced in version 2.6. As a result, our legacy code makes copious use of dynamic scope. Mostly due to inertia and resource constraints, we’ve been stuck on Puppet 2.7 (we should be on 3.7 by April, posts forthcoming). Puppet 2.7 has a lot of disadvantages for us especially given how fast our environment and the community have moved around it. The version of Puppet we’re stuck on has a lot of bugs and is not particularly performant. To move to Puppet 3 we knew we needed to train hundreds of developers and refactor a ton of code, which meant that the transition away from Puppet 2.7 would take a long time. At the same time, lengthy Puppet run times became intolerable to maintain velocity with our Continuous Deployment efforts.
We needed a way to reduce Puppet run times with Puppet 2.7. Since we’re a fairly data-driven bunch, our first step was to gather some performance data. A quick look at our Puppet report data told us that the File resource was responsible for over 30% of our Puppet run time. Looking for more granular information, we configured Logstash to watch our Apache logs and send the API endpoint response times to Graphite. A trend quickly emerged; the median response time for the
file_metadataendpoint was over 1 second (!!). In our environment, thefile_metadataendpoint is the most frequently hit endpoint. An average Puppet run hits this endpoint well over a hundred times. Enter Puppet 3.We’ve been preparing for Puppet 3 for the past year or so. Around this time we began standing up pairs of Puppet 3 masters in each environment, similar to our Puppet 2.7 setup. Initial tests confirmed the fact that Puppet 3 is indeed much faster than Puppet 2.7 (this shouldn’t be a surprise to anybody). Mostly as a thought experiment, I decided to try proxying the
file_metadataandfile_contentendpoints to our Puppet 3 masters in our development environment. The results were pretty interesting. Here’s a snapshot from our Grafana dashboard showing the median response times for thefile_metadataAPI endpoints: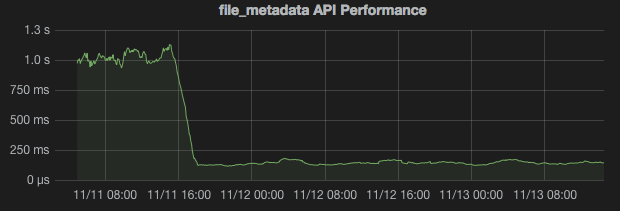
As you can see, our API response times dropped from upwards of 1 second to under 200ms for thefile_metadataendpoints. After exhaustive testing, we found that this reduced our Puppet run times by about a third (!!). Our CD team was very excited to see their Jenkins jobs speeding up. We’ve implemented this offloading configuration across all environments.Here’s what the architecture looks like:
graph TB; cl{Clients}-- https -->lb1(Front End Balancer); lb1-- https -->m1[Puppet 2.7 Mastermaster1.example.com]; lb1-- https -->m2[Puppet 2.7 Mastermaster2.example.com]; m1-- http -->lb2(Back End Balancer); m2-- http -->lb2; lb2-- http -->fs1[Puppet 3.7 Mastermaster3.example.com]; lb2-- http -->fs2[Puppet 3.7 Mastermaster4.example.com];The Puppet 2.7 clients connect to the Puppet masters via the
Front End Balanceron the standard port. The load balancer sends the connection to one of the two Puppet 2.7 masters. From there, we use Apache to proxy all traffic headed for thefile_content,file_metadata, orfile_metadatasendpoints to theBack End Balanceron port 18141 which balances this traffic among the back end file servers.Let’s take a look at some of the configurations we used to make this happen:
Front End Configuration
Here’s the Apache configuration file for the Puppet 2.7 Masters (of particular note are lines 35-42):
Listen 8140 <VirtualHost *:8140> SSLEngine on SSLProtocol all -SSLv2 -SSLv3 SSLCipherSuite ALL:!aNULL:!eNULL:!DES:!3DES:!IDEA:!SEED:!DSS:!PSK:!RC4:!MD5:+HIGH:+MEDIUM:!LOW:!SSLv2:!EXP SSLCertificateFile /var/lib/puppet/ssl/certs/master1.example.com.pem SSLCertificateKeyFile /var/lib/puppet/ssl/private_keys/master1.example.com.pem SSLCertificateChainFile /var/lib/puppet/ssl/ca/ca_crt.pem SSLCACertificateFile /var/lib/puppet/ssl/ca/ca_crt.pem SSLCARevocationFile /var/lib/puppet/ssl/ca/ca_crl.pem SSLVerifyClient optional SSLVerifyDepth 1 SSLOptions +StdEnvVars +ExportCertData RequestHeader set X-SSL-Subject %{SSL_CLIENT_S_DN}e RequestHeader set X-SSL-Client-DN %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-Verify %{SSL_CLIENT_VERIFY}e SetEnvIf X-SSL-Subject "(.*)" SSL_CLIENT_S_DN=$1 SetEnvIf X-Client-Verify "(.*)" SSL_CLIENT_VERIFY=$1 SetEnvIf X-Forwarded-For "(.*)" REMOTE_ADDR=$1 RackAutoDetect On DocumentRoot /etc/puppet/rack/public/ <Directory /etc/puppet/rack/> Options None AllowOverride None Order allow,deny allow from all </Directory> ProxyPreserveHost On ProxyPassMatch ^(/.*?)/file_(.*)/(.*)$ balancer://puppetfileserver ProxyPassReverse ^(/.*?)/file_(.*)/(.*)$ balancer://puppetfileserver <Proxy balancer://puppetfileserver> BalancerMember http://master3.example.com:18141 ping=5 disablereuse=on retry=5 ttl=120 BalancerMember http://master4.example.com:18141 ping=5 disablereuse=on retry=5 ttl=120 </Proxy> ErrorLog /var/log/httpd/puppet_error.log LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" api CustomLog /var/log/httpd/puppet_access.log api </VirtualHost>We’re unable to manage the Apache configuration on our 2.7 masters with the
puppetlabs/apachemodule (it doesn’t work with the version of 2.7 we’re stuck on), otherwise I would’ve provided a code snippet (see below for the Puppet 3 masters). It should be fairly easy to construct anapache::vhostdefinition from the configuration above.Back End Configuration
Here’s the
apache::vhostdefinition for the backend file servers.apache::vhost { "${::fqdn}-fileserver": port => 18141, serveraliases => $::fqdn, docroot => '/etc/puppet/rack/public/', directories => [{ path => '/etc/puppet/rack/', options => 'None', allow_override => 'None', order => 'Allow,Deny', allow => ['from master1.example.com', 'from master2.example.com'], }], setenvif => [ 'X-Client-Verify "(.*)" SSL_CLIENT_VERIFY = $1', 'X-SSL-Client-DN "(.*)" SSL_CLIENT_S_DN = $1', ], custom_fragment => ' PassengerEnabled on', }Which results in this Apache configuration file:
# ************************************ # Vhost template in module puppetlabs-apache # Managed by Puppet # ************************************ <VirtualHost *:18141> ServerName master4.example.com-fileserver ## Vhost docroot DocumentRoot "/etc/puppet/rack/pubilc/" ## Directories, there should at least be a declaration for /etc/puppet/rack/pubilc/ <Directory "/etc/puppet/rack/"> Options None AllowOverride None Order Allow,Deny Allow from master1.example.com Allow from master2.example.com </Directory> ## Logging ErrorLog "/var/log/httpd/master4.example.com-fileserver_error.log" ServerSignature Off ## Server aliases ServerAlias master4.example.com SetEnvIf X-Client-Verify "(.*)" SSL_CLIENT_VERIFY=$1 SetEnvIf X-SSL-Client-DN "(.*)" SSL_CLIENT_S_DN=$1 ## Custom fragment PassengerEnabled On </VirtualHost>This was a relatively small amount of work for a huge payoff. We’ve been able to meet the demand for quicker Puppet runs, while allowing us to take the time we need to have a measured transition to Puppet 3. The plan is to simply point our clients at the new master cluster once the codebase is updated. I’ll write a lot more on how we managed to transition. Hopefully the upgrade to Puppet 4 will happen much more quickly (I’m targeting the end of CY15 for that).
Is this interesting/helpful? Can you think of a better way to do this? Am I the only one doing something like this?! Let me know!
-
The Seven Habits of Highly Effective Puppet Users: Think like a software developer
This post originally appeared on the Constant Contact Tech Blog. I’m reposting it here for continuity.
I gave a talk at PuppetConf 2014 entitled “The Seven Habits of Highly Effective Puppet Users” based on a collection of observations that I’ve made over the years regarding high-functioning Puppet users. These users exhibit common behaviors that go far beyond policies and procedures. These behaviors are broadly understood by team members and nearly universally adhered to. It’s clear that these habits lead to more stable, maintainable, and well-understood Puppet deployments. This is the first in a series of blog posts discussing those seven habits.
Habit 1: Think like a software developer
By far, the most consequential habit exhibited by highly effective Puppet users is the tendency to think like a software developer. Much to the chagrin of many folks in the field, infrastructure as code has fundamentally changed the practice of system administration. This change is so great that it warrants a redefinition of the job. I hate to be the bearer of bad news, but you’re not a system administrator anymore; you’re a software developer. If you want to keep up with the industry, you’re going to need to re-tool. The sooner you make peace with this fact, the sooner you can start working on taking your skill set (and your Puppet code) to the next level.
I wasn’t the only speaker preaching this at PuppetConf, it was a consistent theme throughout the entire conference. If you want to really put Puppet to work, you need to move beyond package-file-service and resource declarations. You need to approach Puppet from the perspective of a software developer. Puppet’s strengths are in its extensibility and flexibility. If you’re still approaching Puppet as if it’s just a collection of data, you’re never going to really harness Puppet’s core power. If you’re writing Puppet, you’re writing software. I know, it’s very meta and can be hard for some people to wrap their minds around, but the first step is to realize that Puppet is a real programming language.
Puppet is a Domain Specific Language (DSL) and, consequently, is missing a lot of the features of a general-purpose language. This isn’t a flaw; it’s a design decision. A DSL allows the user to focus on the problem domain instead of the language. The whole idea of a DSL is that language is an impediment; we need to get the language out of the way of the real work. We may have gone a little too far with this. We thought Puppet’s DSL would allow system administrators to write good code without having to learn what good code looks like. Instead, all this did was make it easier for them to write really bad code. Part of thinking like a software developer is taking the time to know the language inside and out. Once you shift the focus onto the language a little more, you will completely change your approach to Puppet, for the better.
So, what does this really mean? It means that you’re going to have to do some digging to figure out exactly what a software developer does. You’re going to have to learn the lingo and understand how to do things like:
- continuous integration
- release engineering
- code review
- documentation
- test driven development
These things are fairly foreign to system administrators, but they’re about to become central to your new job description. Luckily, I’m here to help. Over the course of this blog series, I’m going to touch on many of these topics. Stay tuned!